Many website generate superfluous queries, which can pollute your page list unnecessarily and can give you some headaches. That is the reason behind the "ignore queries" feature, to weed these things out.
We want to start with an important warning: be very careful running discovery and/or scan without a limit. We advise you to start with low limit, which then you can increase gradually. Indeed, that is the reasoning behind the default value (100). Webshops, product catalogs and other pages that have complex querys and the potential to generate virtually unlimited URLs, and that can eat up your Easyling quotas very quickly, generating a lot of unnecessary costs for you, besides the pollution of your page list.
With a well-configured ignore query, you can dramatically cut down the amount of pages Easyling has to crawl.
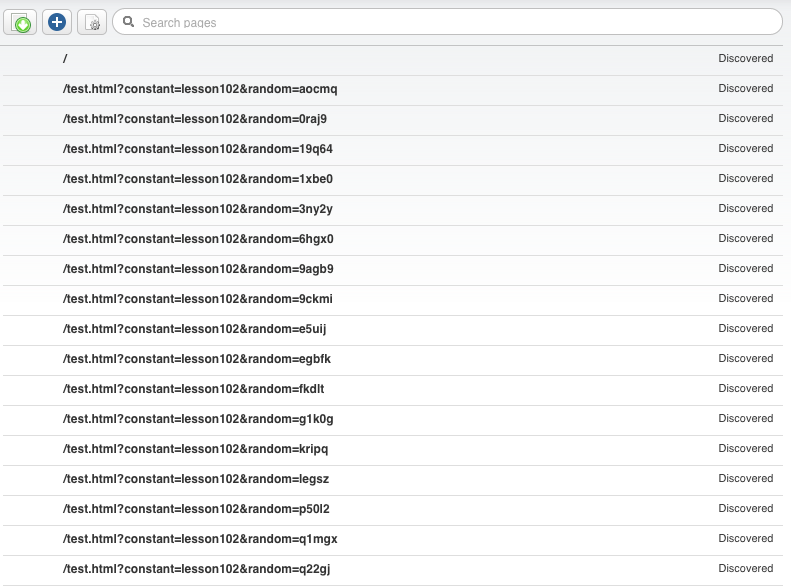
As a first step, create a new project with this site's URL (lesson102.tutorial.easyling.com), run a discovery on this page, then check your page list. Below are twenty links for the same page (/test.html), but with different URLs.
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19Sure enough, you will end up with 20 different pages. If you check your page list, you will see something like this:
To fix this, you have to add 'random' to your ignore query list and then press discover again.
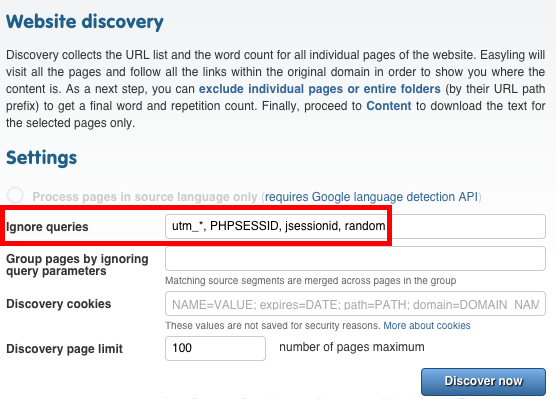
Note that there is another option there, to group pages by ignoring query parameters: this is for pages that share a large amount of content, and serves a very different purpose. It should not be used in this case.
For now, it is not possible to clean the page list; you can either exclude the duplicate pages, or, if you are just starting the project, simply start a new one with the correct ignore query settings. You can exclude pages with certain prefixes (we do not have pattern matching just yet), or by hand on the page list.
It is also important to note, that if you have a webpage with several existing translations, you should exclude those, so they are not crawled unnecessarily.
There are a couple of default values that Easyling provides for the ignore queries:
There is an important thing to note on pages with dynamic content: if you have several pages and you put a certain query parameter into the ignore list, Easyling will only pick up the first page. However, if you visit those pages manually, they will be picked up and merged into the first page in the Translation Workbench.
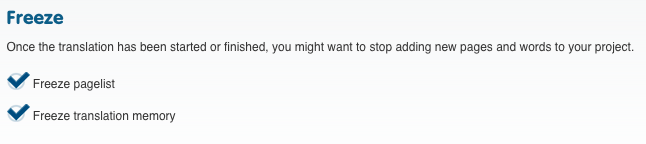
A related feature to note here is fact that you can freeze the pagelist and the memory once you start the translation. You can find this option at Dashboard - Advanced Settings - Pattern Matching. That prevents you from picking up new content from the page, at least until it is done.
Freezing the page list prevents you from adding new pages to the translation until it is done, if you do another scan on your page. Note that if you only freeze the page list, but not the memory, you will still pick up new content from the pages.
You can always override this when discovering or scanning pages with the checkboxes below:
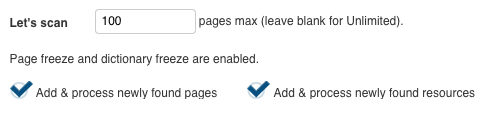
It is advised to freeze the pagelist once you start translation, so you can track the progress more consistently and not have pages added mid-translation.
It can useful even after publishing the page, to prevent unnecessary pages added, which can happen when big search engines' bots (and sometimes even users) try to visit unnecessary pages, or a user logs into the admin of the CMS from a translated page. The latter would add the pages from the admin to your project.